[Prometheus] Prometheus Thanos 아키텍처 살펴보기
l Prometheous with Thanos
Thanos(타노스)는 CNCF(https://www.cncf.io/)의 인큐베이팅 프로젝트로, 프로메테우스의 확장성과 내구성을 향상시키기 위한 오픈소스 프로젝트이다.
l Prometheus 확장 및 내구성을 위한 다양한 구성 방법 : https://sqlmvp.tistory.com/1521
Thanos는 Prometheus 2.0 스토리지 형식을 활용하여 빠른 쿼리 대기 시간을 유지하면서 모든 개체 스토리지에 메트릭 데이터를 효율적으로 저장한다. 또한 운영중인 프로메테우스 서버의 데이터를 통합 저장 및 외부 저장소에 데이터를 저장할 수 있기 때문에 보관 기간에 제한이 없고, 단일 쿼리로 전체 프로메테우스 서버의 데이터를 쿼리 할 수 있다. 장점을 크게 정리하면 아래와 같이 정리할 수 있다.
l Long-term Storage : 원격 스토리지에 데이터를 안정적으로 저장하여 장기적인 데이터 보존을 가능
l Global Query : 여러 원격 스토리지에서 데이터를 통합하여 조회할 수 있는 Global Query 기능을 제공하여 분산된 데이터에 대해 단일 쿼리를 실행할 수 있어 데이터 분석과 모니터링에 유용
l HA(고가용성) : 원격 스토리지에 데이터를 복제하여 프로메테우스 서버 중 하나가 장애가 발생하더라도 데이터의 고가용성을 보장
타노스는 Sidecar, Query Gateway, Store Gateway, Compactor, Ruler, Receiver라는 6개의 컴포넌트로 이루어져 있다.
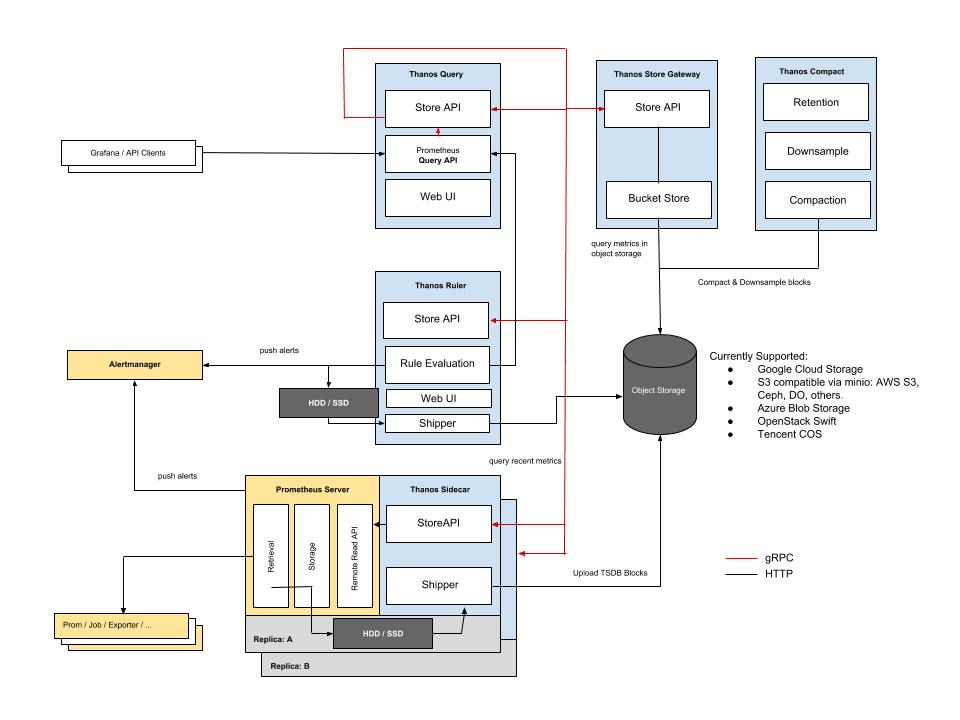
l Thanos Sidecar
ü Prometheus와 함께 하나의 POD로 배포되어 기존 프로메테우스 서버와 통합
ü Prometheus 데이터를 Object Storage 버킷에 백업하고 다른 Thanos 구성 요소가 gRPC API를 통해 Sidecar가 연결된 Prometheus 인스턴스에 액세스
ü 2시간마다 프로메테우스 메트릭을 객체 스토리지로 보냄
ü 사이드카는 Prometheus 끝점을 사용. --web.enable-lifecycle 플래그로 활성화
l Thanos Query Gateway
ü PromQL을 처리하는 부분으로 필요한 Prometheus의 sidecar와 연결
ü 질의를 Store (Store API), Sidecar등으로 전달하고 수집
ü 타노스의 전역 쿼리 계층(Global query layer)을 사용하여 모든 프로메테우스 인스턴스에 대해 PromQL를 사용하여 한번에 조회가능
ü 쿼리 구성 요소는 상태 비저장이며 수평 확장이 가능하며 여러 복제본과 함께 배포 가능
ü 사이드카에 연결되면 주어진 PromQL 쿼리를 위해 어떤 프로메테우스 서버에 접속해야 하는지 자동으로 감지
ü 단일 Thanos 쿼리 엔드 포인트에서 여러 메트릭 백엔드를 집계하고 중복 제거하는 기능을 제공
l Thanos Store Gateway
ü Store와 같은 개념이며, API Gateway 역할을 하며 오브젝트 스토리지에 접근하는 모든 작업은 Store API를 사용
ü Query, Receive, Ruler 등에 존재
ü 사이드카와 동일한 gRPC 데이터 API로 구성되어 있지만 개체 저장소 버킷에서 찾을 수 있는 데이터로 백업
ü 스토어 게이트웨이는 오브젝트 스토리지 데이터에 대한 기본 정보를 캐싱 하기위해 소량의 디스크 공간을 차지 (타노스 쿼리 저장소 역할)
l Thanos Compactor
ü 오브젝트 스토리지에 저장된 블록 데이터를 압축하여 저장공간 최적화 작업 진행
ü 개체 저장소를 간단히 스캔하고 필요한 경우 압축을 처리
ü 동시에 쿼리 속도를 높이기 위해 다운 샘플링된 데이터 복세본을 만드는 역할 수행
ü 주기적 배치 작업으로 실행하거나 데이터를 빨리 압축하기 위해 상시 실행 상태로 둘 수 있음
ü 데이터 처리를 위해 100GB ~ 300GB의 로컬 디스크 공간을 제공하는 것이 좋음
ü 동시성이 보장되지 않으므로 전체 클러스터에서 싱글톤 형식으로 배포하고 버킷에서 데이터를 수동으로 수정할 때 실행하면 안됨
l Thanos Ruler
ü 타노스 사이드카가 적용된 프로메테우스의 보존기간이 충분하지 않거나 전체 보기가 필요한 알림 또는 규칙 구성
ü Thanos 쿼리 구성 요소에 연결하고 Prometheus Alert 및 Record 규칙을 평가
ü Prometheus Alert Manager를 사용하여 Alert를 트리거 할 수 있음
l Thanos Receiver
ü 프로메테우스 서버에서 remote_write를 통해 메트릭 데이터 수신할 때 사용
ü 기본 2시간 단위로 TSDB 블록을 만들어 오브젝트 스토리지에 저장
위 아키텍처를 살펴보고 요악하면 다음과 같은 활용을 구상해 볼 수 있다.
l 다수의 프로메테우스 서버를 Global Query view기능을 통해 하나의 인터페이스로 조회 및 활용
l Global Query view, 메트릭 duplication 기능으로 프로메테우스 서버가 장애나더라도 서비스 단절이나 데이터 손실 방지
l 외부 저장소를 활용할 수 있으므로 데이터 크기에 따른 스토리지 성능 하락에 대비할 수 있고, 메트릭 데이터를 영구 보관할 수 있으므로 다양하게 활용 가능
[참고자료]
l Thanos공식 문서 : https://thanos.io/v0.6/thanos/getting-started.md/
l Multi-Cluster Monitoring with Thanos : https://particule.io/en/blog/thanos-monitoring/
2023-06-29 / Sungwook Kang / https://sungwookkang.com
프로메테우스, Prometheus, 모니터링 시스템, Grafana, 그라파나, DevOps, 데브옵스, Kubernetes, 쿠버네티스, 타노스, Thanos, CNCF
'SW Engineering > DevOps, SRE' 카테고리의 다른 글
| [Kubernetes] 쿠버네티스에서 파드 생성시 프라이빗 레지스트리 이미지 사용하기 (0) | 2023.08.09 |
|---|---|
| [Kubernetes] vagrant 환경에서 Kubernetes 클러스터 구성하기 (0) | 2023.07.04 |
| [Prometheus] Prometheus 확장 및 내구성을 위한 다양한 구성 방법들 (0) | 2023.06.28 |
| [Prometheus] Prometheus 구조 및 개념 (0) | 2023.06.28 |
| Kubernetes 장점 (0) | 2021.07.31 |