[Prometheus] Prometheus 확장 및 내구성을 위한 다양한 구성 방법들
l Prometheous with Thanos
Prometheus(프로메테우스) 모니터링 시스템은 오픈 소스 기반의 모니터링 시스템으로 Kubernetes(쿠버네티스) 활성화 함께 많이 사용되고 있다. 프로메테우스는 구조가 간단하며, 운영이 쉽고 강력한 쿼리 기능을 가지고 있다. 간단한 텍스트 형식으로 메트릭 데이터를 쉽게 익스포트 할 수 있으며, key-value 형식의 데이터 모델을 사용한다. 수집된 데이터는 Grafana(그라파나)를 통해 시각화를 제공한다.
l Prometheus 구조 및 개념 : https://sqlmvp.tistory.com/1520
프로메테우스의 가장 큰 약점은 확장성과 가용성이다. 프로메테우스는 클러스터가 지원되지 않는 독립형 서비스로, 프로메테우스 서버 장애시 메트릭을 수집할 수 없다는 것이다. 프로메테우스 서버의 장애시간 또는 재설정 등으로 서버 또는 서비스가 재시작 될 동안 타켓에 대한 모니터링을 할 수 없다면 이는 서비스를 운영하는데 매우 큰 리스크이다. 이러한 문제를 해결하기 위해 여러가지 프로메테우스 서버 구성에 대한 아키텍처를 생각해 볼 수 있다.
[프로메테우스N 구성으로 타켓 서버 중복 모니터링]
두 대이상의 프로메테우스 서버를 구성하여, 각 프로메테우스 서버에서 타겟 서버를 교차해서 메트릭을 수집하는 방식이다.
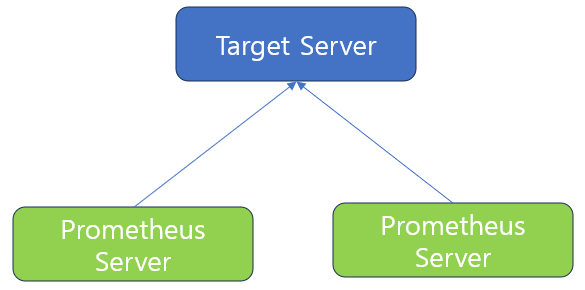
이러한 방식으로 구성할 경우 관리 해야하는 프로메테우스 서버도 증가하지만, 모니터링 대상이 되는 타겟 서버 입장에서도 여러 프로메테우스 서버로부터 요청되는 메트릭 데이터를 수집 및 전달하기 위해 오버헤드가 발생한다. 또한 프로메테우스로 수집된 데이터를 분석할 때에도, 특정 시점에 장애가 번갈아 발생시, 데이터가 한쪽에만 있게 되므로 중앙에서 한번에 분석하기 불편한 단점이 있다.
[프로메테우스 Federation 구성]
프로메테우스 서버를 여러 대 구성하고, 프로메테우스 서버가 다른 프로메테우스 서버로 요청하여 데이터를 수집할 수 있다.
l Hierarchical Federation 구성은 프로메테우스 서버 사이에 계층을 두고 Tree 형태로 Federation을 구성하는 방법이다. 부모 프로메테우스는 자식 프로메테우스들의 통합 메트릭 제공 및 통합 메트릭을 기반으로 알람을 제공하는 용도로 사용할 수 있다.
l Cross-service Federation 구성은 동일 레벨의 프로메테우스 서버사이를 Federation으로 구성하는 방법이다.

Federation으로 구성할 경우, 각 프로메테우스 서버는 타겟 서버로부터 일정 주기로 데이터를 수집하고 저장하고, 부모(중앙) 프로메테우스 서버는 각 프로메테우스 서버로부터 저장된 데이터를 별도의 주기로 수집할 수 있어, 데이터양이 많을 때, 평균값이나 해상도 등을 조정할 수 있다. 예를들면 각 프로메테우스 서버는 10초 단위로 수집하고, 중앙 프로메테우스는 1 분 단위로 하위 프로메테우스 서버로 요청하여 평균값 등을 이용할 수 있다. 하지만 각 프로메테우스 서버 장애 시 데이터 유실, 데이터 증가로 인한 중앙 프로메테우스 서버의 오버헤드 증가 문제가 있으므로 일정 규모 이상에서는 적용하기 힘든 부분이 있다.
[프로메테우스 Thanos 구성]
Thanos는 프로메테우스의 확장성과 내구성을 향상 시키기 위한 오픈소스 프로젝트로, 프로메테우스의 메트릭 데이터를 분산된 원격 스토리지에 저장하고 조회할 수 있는 기능을 제공한다. 아래 그림에서 서드파티 스토리지로 데이터를 저장하기 위한 Adapter 역할이 Thanos의 기능이다.

l Thanos를 사용하여 구성 할 경우 아래와 같은 장점이 있다.
l Long-term Storage: 원격 스토리지에 데이터를 안정적으로 저장하여 장기적인 데이터 보존을 가능
l Global Query: 여러 원격 스토리지에서 데이터를 통합하여 조회할 수 있는 Global Query 기능을 제공하여 분산된 데이터에 대해 단일 쿼리를 실행할 수 있어 데이터 분석과 모니터링에 유용
l HA(고가용성): 원격 스토리지에 데이터를 복제하여 프로메테우스 서버 중 하나가 장애가 발생하더라도 데이터의 고가용성을 보장
프로메테우스 Thanos 구성으로 데이터를 수집하여 S3에 저장하는 구성하는 구조를 만든다면 아래와 같은 형식으로 아키텍처를 디자인 할 수 있다.
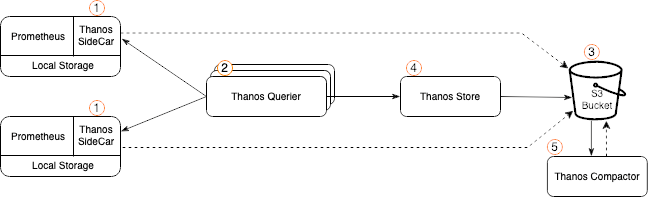
1. Prometheus용 Thanos 사이드카를 활성화
2. Sidecar와 대화할 수 있는 기능이 있는 Thanos Querier를 배포
3. Thanos Sidecar가 S3 버킷에 Prometheus 메트릭을 업로드할 수 있는지 확인
4. Thanos Store를 배포하여 장기 스토리지(이 경우 S3 버킷)에 저장된 메트릭 데이터를 검색
5. 데이터 압축 및 다운 샘플링을 위해 Thanos Compactor를 설정
다양한 구성으로 프로메테우스의 단점인 확장 및 내구성을 보완하는 방법에 대해서 살펴보았다. 여러 방식이 있겠지만 현재 대규모 서비스에서는 Thanos 구성이 가장 많이 사용되는 듯 하다. Thanos의 아키텍처 및 자세한 내용은 다른 포스트에서 다뤄볼 예정이다. 모니터링을 구성하는데 있어서 정답은 없다. 항상 우리가 가진 리소스 및 환경에서 가장 최선의 방법을 잘 찾는 것이 중요할 듯 하다.
참고자료 :
l https://wikitech.wikimedia.org/wiki/File:Prometheus_federation.png
{kind=link}
l https://prometheus.io/docs/prometheus/latest/federation/
l https://www.robustperception.io/federation-what-is-it-good-for/
l https://thanos.io/v0.6/thanos/getting-started.md/
l https://particule.io/en/blog/thanos-monitoring/
2023-06-28 / Sungwook Kang / https://sungwookkang.com
프로메테우스, Prometheus, 모니터링 시스템, Grafana, 그라파나, DevOps, 데브옵스, Kubernetes, 쿠버네티스
'SW Engineering > DevOps, SRE' 카테고리의 다른 글
| [Kubernetes] vagrant 환경에서 Kubernetes 클러스터 구성하기 (0) | 2023.07.04 |
|---|---|
| [Prometheus] Prometheus Thanos 아키텍처 살펴보기 (0) | 2023.06.29 |
| [Prometheus] Prometheus 구조 및 개념 (0) | 2023.06.28 |
| Kubernetes 장점 (0) | 2021.07.31 |
| Kubernetes 마스터 노드, 워커 노드 (0) | 2021.07.29 |