[Kafka] Kafka 리더, 팔로워, 복제 및 복구 이해하기
l Kafka
Kafka (이하”카프카”)는 분산 처리 시스템으로 서버에 물리적인 장애가 발생하여도 높은 가용성을 보장하도록 구성할 수 있다. 그리고 가용성을 보장하기 위해 데이터를 여러 노드로 분산해서 운영한다. 메시지를 여러 개로 복사해서 카프카 클러스터의 여러 브로커들에게 분산시키는데 이러한 작업을 “리플리케이션”이라 한다. 이때 실제로 리플리케이션되는 정보는 토픽이 아닌 토픽의 파티션이다. 토픽에 대한 자세한 내용은 아래 글을 참고한다.
l Kafka 데이터 모델인 Topic과 Partition 이해하기 : https://sungwookkang.com/entry/Kafka-Kafka-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%AA%A8%EB%8D%B8%EC%9D%B8-Topic%EA%B3%BC-Partition-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0
카프카는 내부적으로 클러스터내에서 동일한 리플리케이션들에 대해서 리더와 팔로워로 구분하여 역할을 분담하고 있다. 그리고 리더는 리플리케이션중에 하나가 선정되며, 모든 읽기와 쓰기는 리더를 통해서만 수행된다. 프로듀서는 모든 브로커들에게 메시지를 보내는 것이 아닌 리더에게만 메시지를 전송한다. 또한 컨슈머도 리더에게만 메시지를 가져온다. 그리고 팔로워들은 리더에서 토픽 파티션을 복제한다. 즉, 팔로워는 리더가 새로운 메시지를 받았는지 확인하고 새로운 메시지가 있으면 해당 메시지를 리더 파티션으로부터 복제한다. 이러한 과정을 통해 리더를 담당하는 브로커에 장애가 발생하더라도 복제되고 있는 팔로워들이 언제든 리더로 대체될 수 있다.

그림을 보면 프로듀서가 broker1의 topic1로 메시지를 보내는 것을 확인할 수 있는데, 이 상태는 topic1에 대한 리더는 broker1이 담당하고 있다는 뜻이다. 그리고 팔로워인 broker2, broker3에서 데이터를 복제한다. 그리고 한 가지 주의해야 할 사항이 모든 토픽에 대한 리더가 broker1이 아니라는 것이다. 그림에서 각 리더가 토픽별로 각 브로커에 분산된 것을 볼 수 있는데, 토픽 생성시 여러 브로커에 토픽을 생성하며 이때 리더를 선출하기 때문에 모두 같은 브로커에서 리더가 되는 것은 아니다. 이러한 구조 때문에 프로듀서와 컨슈머에 대한 부분도 부하 분산이 가능한 구조로 되어 있다.
아래 명령어를 사용하면 토픽별로 어느 브로커에서 리더로 선출되어 있는지 확인할 수 있다.
| kafka-topics.sh --bootstrap-server=XXX.XXX.XXX.XXX:9092 --describe topic1 |

l Topic : 토픽의 이름을 나타낸다.
l ReplicationFactor : 원본을 포함한 리플리케이션 개수를 나타낸다.
l Leader : 해당 토픽의 리더 브로커를 나타낸다.
l Replicas : 해당 토픽이 복제되어 있는 브로커를 나타낸다.
l Isr : in sync replica로 파티션 리더 브로커와 함께 현재 동기화되고 있는 최신 상태의 복제본을 나타낸다.
[복제 유지와 커밋, 복구 과정]
카프카에서 복제와, 커밋, 그리고 브로커가 다운된 후 리더와 팔로우의 역할 변경 이후 데이터가 복구되는 과정을 살펴본다.
1. 프로듀서가 리더를 통해 Message1을 입력한다. 그리고 팔로워는 Message1에 대해서 복제를 완료한 상태이다.

2. 프로듀서가 리더로 Message2를 입력한다. 그리고 아직 팔로워로는 Message2가 복제되지 않은 상태이다.
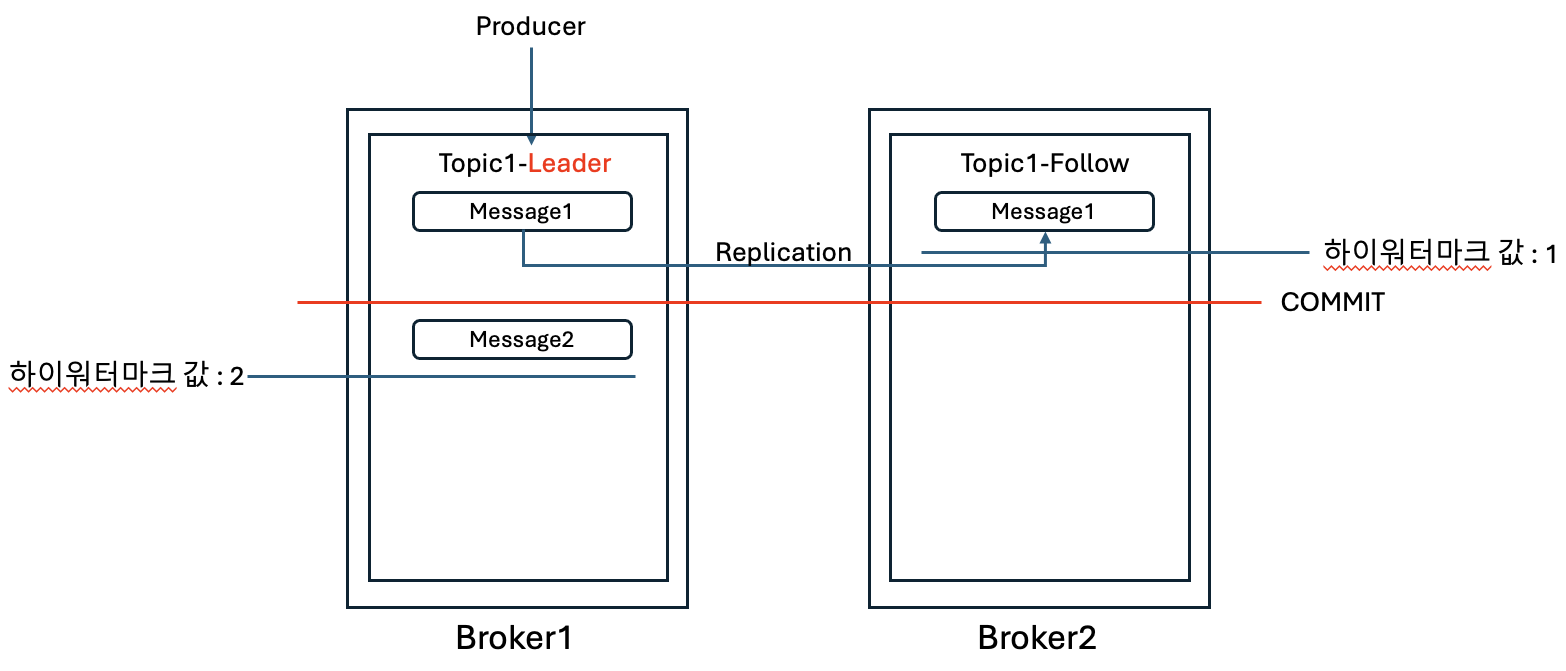
3. Message2가 팔로워로 복제되기 전에 현재 리더 역할을 하는 Broker1이 다운되었다.

4. 기존에 팔로워 역할을 하던 Broker2가 리더로 역할이 변경되고, 프로듀서는 리더로 Message3을 입력한다.

5. 다운되었던 Broker1이 복구되고, 팔로워 역할로 수행된다. 그런데 이때, 새로운 리더(Broker2)와 팔로워(Broker1)의 데이터가 불일치하는 부분이 있음이 확인된다.

6. 팔로워는 리더에 포크 요청을 하고, 불일치하는 과거 데이터 Message2는 삭제하고, 최신의 데이터 Message3를 복제하고 최신의 데이터가 유지된다.
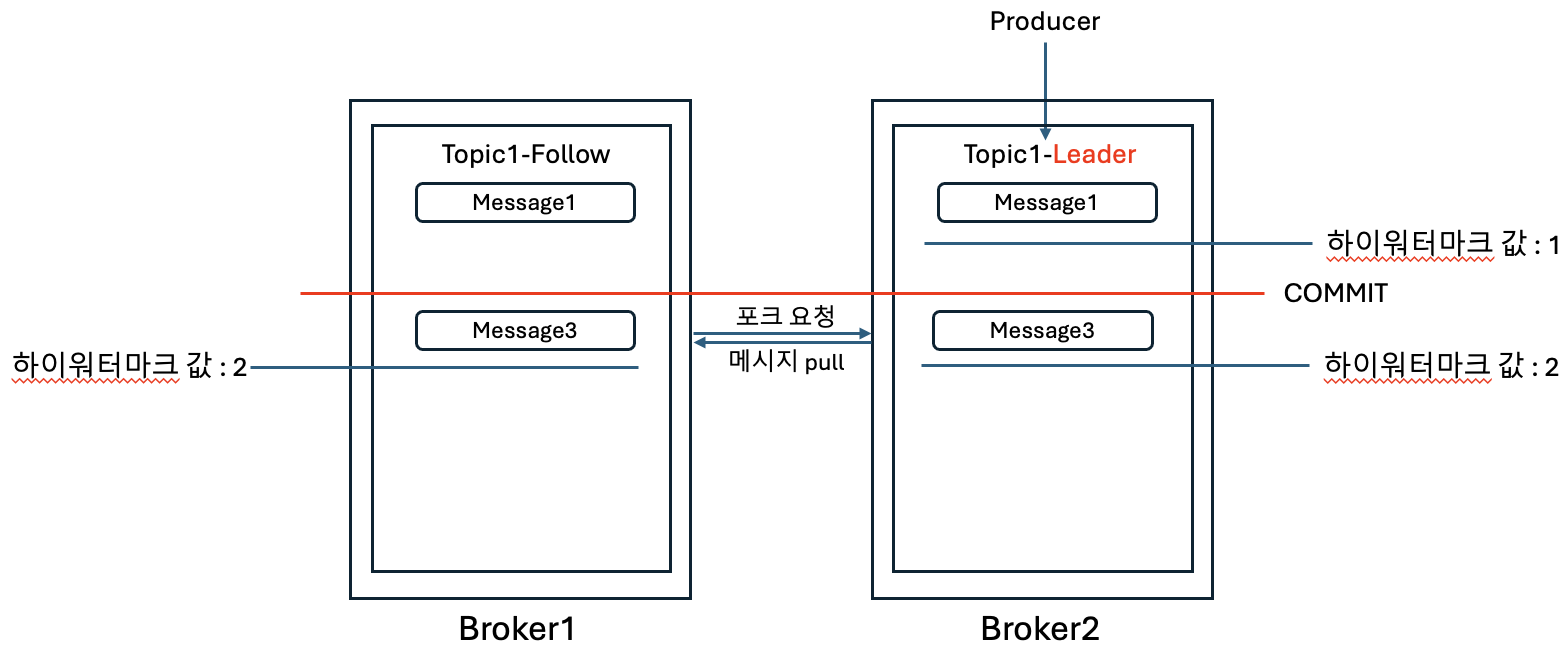
카프카는 분산처리 시스템이기 때문에 높은 가용성을 제공하지만, 예상하지 못한 시스템 장애가 발생하였을 경우에 시점에 따라 데이터 불일치가 발생하는 부분이 발생할 수 있으며 이때 복구 과정에서의 데이터 유실 또는 불일치 부분이 발생할 수 있다. 이와 같은 카프카의 특징을 알고 있으면, 장애상황에 대한 대처 및 장애조치 후 사이드 이펙트에 대해서도 예상할 수 있게 된다.
[참고자료]
https://www.confluent.io/blog/hands-free-kafka-replication-a-lesson-in-operational-simplicity/
https://www.conduktor.io/kafka/kafka-topic-replication/
2024-01-19 / Sungwook Kang / https://sungwookkang.com
KAFKA, 아파치 카프카, Apache Kafka, 카프카 토픽, 카프카 파티션, Kafka Topic, Kafka Partition, 카프카 복제, Kafka Replication
'SW Engineering > DevOps, SRE' 카테고리의 다른 글
| [Kafka] Kafka 컨슈머(Consumer) 이해하기 (0) | 2024.01.23 |
|---|---|
| [Kafka] Kafka 프로듀서(Producer) 이해하기 (0) | 2024.01.22 |
| [Kafka] Kafka 데이터 모델인 Topic과 Partition 이해하기 (0) | 2024.01.18 |
| [Kafka] Kafka 클러스터 4노드 구성 - Controller, Broker 혼합해서 구성하기 (0) | 2024.01.17 |
| [Kafka] KRaft 설정 파일 및 기본 속성 정의 알아보기 (0) | 2024.01.11 |