[Kafka] Kafka 데이터 모델인 Topic과 Partition 이해하기
l Kafka
Kafka(이하 “카프카”)에는 토픽(Topic)과 파티션(Partition)이라는 데이터 모델이 있다. 간단히 정리하면 토픽은 메시지를 받을 수 있도록 논리적으로 묶은 개념이고, 파티션은 토픽을 구성하는 물리적 데이터 저장소이며 수평 확장이 가능한 단위이다.
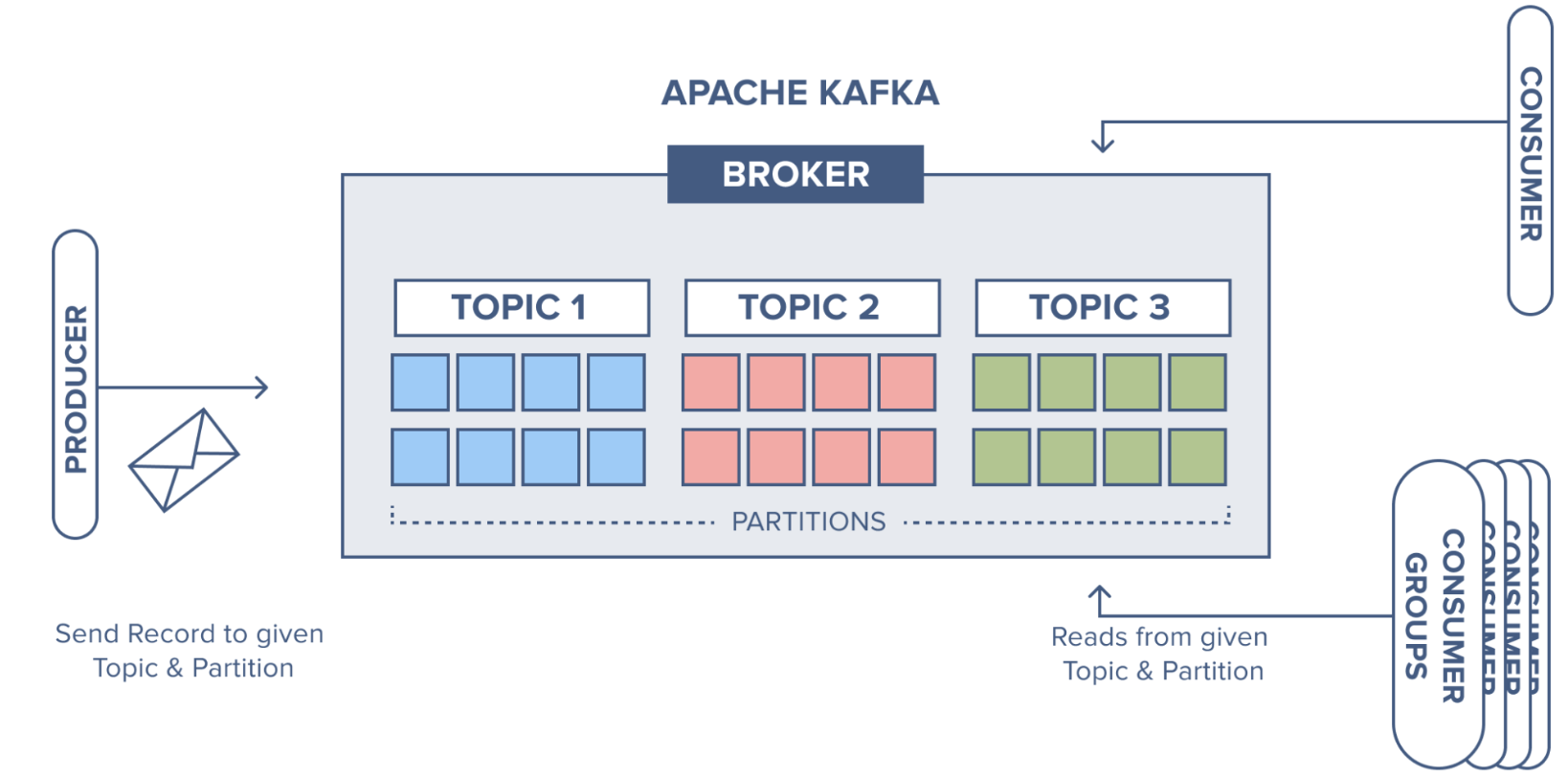
카프카 클러스터는 토픽에 데이터를 저장한다. 토픽의 이름은 249자 미만으로 영문, 숫자, ‘.’, ‘_’, ‘-‘를 조합하여 만들 수 있다.
토픽은 1개 이상의 파티션으로 구성되어 있다. 파티션은 append-only로 동작하며 새 메시지는 파티션 맨 뒤에 추가된다. 그리고 각 메시지의 저장 위치를 offset이라고 한다. 오프셋은 파티션 내에서 메시지를 식별하는 유니크한 값이며 순차적으로 증가하는 64비트 정수 형태로 되어 있으며, 0부터 시작한다.
아래 그림을 보면 토픽에 대한 파티션이 3개가 있고, 메시지는 각 파티션별로 분산되어 저장된다. (그림에서 숫자는 오프셋 위치이다.)

토픽 기준으로 보면, 각 파티션마다 오프셋이 동일하게 존재하지만, 파티션별로 보면 오프셋은 유일하다. 카프카에서는 이 오프셋을 이용하여 메시지의 순서를 보장한다. 그렇기 때문에 파티션 내에서는 순서를 보장하지만 파티션 간에는 데이터 순서를 보장하지 않는다. 그렇기 때문에 순서를 보장해야 하는 메시지의 경우 파티션 설정에 주의해야 한다.
브로커는 하나 이상의 노드들로 이루어지는데, 여러 브로커에 파티션을 수평확장 하였을 경우 아래와 같은 이점이 있다.
l 카프카의 성능은 브로커의 I/O 처리량에 영향을 받는데, 토픽의 모든 파티션을 하나의 브로커에 넣는 것 보다, 분산하였을 경우 I/O 오버헤드도 분산할 수 있다.
l 모든 파티션을 단일 브로커에서 제공하면 지원할 수 있는 Consumer 수가 제한되는데, 여러 브로커에서 파티션을 나누어 제공함으로써 더 많은 Consumer 들이 동시에 토픽의 메시지를 처리할 수 있다.
l 동일한 Consumer의 여러 인스턴스가 서로 다른 브로커에 있는 파티션에 접속함으로써 매우 높은 메시지 처리가 가능하다.
기본적으로 파티션 키는 해시함수를 사용하기 때문에, 동일한 키를 갖는 모든 레코드들이 동일한 파티션에 도착하는 것을 보장한다. 파티션 키를 지정할 경우에는, 관련된 이벤트를 동일한 파티션에 유지함으로써 전달된 순서가 그대로 유지되는 것을 보장할 수 있다. 파티션 키를 사용한 방법이 이벤트의 순서를 보장할 수 있다는 장점을 가진 반면, 키가 제대로 분산되지 않는 경우 특정 브로커만 메시지를 받는 단점도 존재한다.

Producer 가 레코드를 생성할 때 파티션 키를 명시하지 않으면, 카프카는 Round-Robin 방식을 사용해 파티션을 분산한다. 이 경우, 레코드들은 해당 토픽의 파티션들에 균등하게 분배된다. 그러나 파티션 키를 사용하지 않았기 때문에 레코드들의 순서는 보장되지 않는다.
아래 스크립트는 토픽을 생성한다. 이때 복제 수와 파티션 수를 설정할 수 있다.
| bin/kafka-topics.sh --bootstrap-server <host:port> --create --topic <topic-name> \ --partitions 20 --replication-factor 3 --config <configName>=<configValue> |
l Replication-factor : 메시지가 기록될 서버 수를 지정한다. 데이터 컨슘을 중단하지 않고 시스템을 투명하게 서비스할 수 있도록 복제 인수를 2 또는 3으로 사용해야 한다. 예를 들어, 복제 인수를 3으로 지정하면 최대 2개의 서버에 오류가 발생하면 데이터에 대한 액세스가 손실될 수 있다.
l Partitions : 파티션은 토픽을 샤딩의 수를 제어한다. 파티션 수는 여러 가지 영향을 미친다. 각 파티션은 단일 서버에 완전히 맞아야 한다. 따라서 20개의 파티션이 있는 경우 전체 데이터 세트와 읽기 및 쓰기 로드는 20개 이하의 서버 (복제본 제외)에서 처리된다. 마지막으로 파티션 수는 소비자의 최대 병렬 처리에 영향을 미친다.
[참고자료]
https://www.cloudkarafka.com/blog/part1-kafka-for-beginners-what-is-apache-kafka.html
https://docs.confluent.io/kafka/operations-tools/topic-operations.html#topic-operations
2024-01-18 / Sungwook Kang / https://sungwookkang.com
KAFKA, 아파치 카프카, Apache Kafka, 카프카 토픽, 카프카 파티션, Kafka Topic, Kafka Partition
'SW Engineering > DevOps, SRE' 카테고리의 다른 글
| [Kafka] Kafka 프로듀서(Producer) 이해하기 (0) | 2024.01.22 |
|---|---|
| [Kafka] Kafka 리더, 팔로워, 복제 및 복구 이해하기 (0) | 2024.01.19 |
| [Kafka] Kafka 클러스터 4노드 구성 - Controller, Broker 혼합해서 구성하기 (0) | 2024.01.17 |
| [Kafka] KRaft 설정 파일 및 기본 속성 정의 알아보기 (0) | 2024.01.11 |
| [Kafka] Kafka 설치 (with KRaft) 및 PUB/SUB 테스트 코드 (with Python) 실습 (0) | 2024.01.09 |