SQL Server Failover Cluster 구성
l Version : SQL Server 2019
SQL Server의 고가용성 중 하나인 SQL Server Failover Cluster (장애조치 클러스터) 인스턴스를 구성하는 방법에 대해서 알아본다. SQL Server 장애조치 클러스터를 구성하기 위해서는 Windows Failover Cluster이 먼저 구성되어 있어야 한다. 그리고 디스크 또한 공유 디스크를 사용이 필수이다. 이번 포스트에서는 Windows Failover Cluster 구성이 완료 되어 있다는 가정하에 SQL Server Failover Cluster만 구성하는 방법에 대해서 설명한다.
이번 포스트에서 구성하려는 장애조치 클러스터의 구성은 아래 그림과 같다. DB01 은 액티브 서버로 운영되고, DB02는 패시브 서버로 운영되며 비상시 장애조치 되어 역할이 변경된다. SQL Server 운영에 필요한 설치 파일 및 사용자 데이터베이스 파일은 공유 디스크에 저장되어 운영 된다.

[Master 서버, 클러스터 설치]
DB1(Master) 서버에서 SQL Server 설치 파일을 실행한 다음 [설치]-[SQL Server 장애조치(Failover) 클러스터 새로 설치]를 클릭 한다.

사용 조건 단계에서 라이선스 계약에 동의함을 선택하고 [다음]을 클릭한다.

Microsoft 업데이트 단계에서는 업데이트를 체크하지 않고 [다음]을 클릭한다. 업데이트를 클릭하게 되면 설치 과정에서 업데이트가 발생하여 설치 시간이 오래 걸릴 수 있으니, 업데이트는 모든 설치 이후에 별도로 진행 할 수 있도록 한다.

장애 조치(Failover) 클러스터 설치 규칙 단계에서는 클러스터 설치에 적합한 환경인지 등을 검사하게 된다. [다음]을 클릭한다.

기능 선택 단계에서는 사용자에게 필요한 SQL Server 기능을 선택 한다. 설치할 기능을 선택하고 [다음]을 클릭한다.

인스턴스 구성 단계에서는 SQL Server 클러스터에 사용할 네트워크 이름을 입력한다. 이 이름은 이후 다른 서버가 클러스터에 조인할 때 식별할 수 있는 이름이기에 의미 있는 이름으로 지정할 수 있도록 한다. 이름을 입력하였으면 [다음]을 클릭한다.
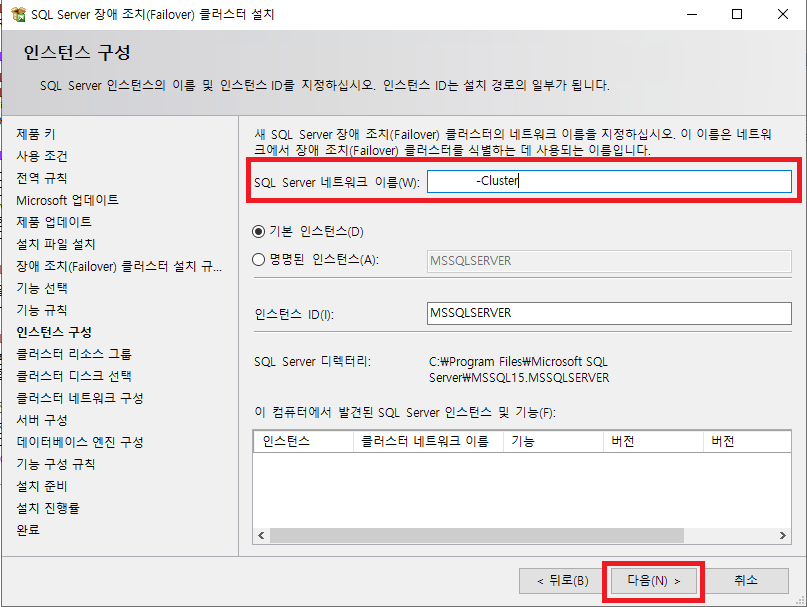
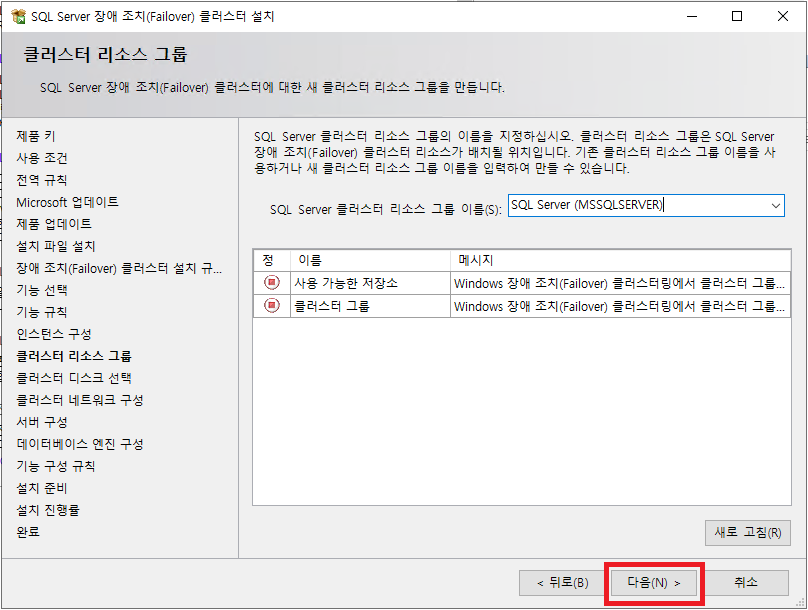
클러스터 리소스 그룹 단계에서는 리소스 그룹에 포함할 인스턴스를 선택한다. 아래 그림에서는 기본 인스턴스로 생성하였기에 그룹 이름 또한 기본 인스턴스 이름으로 보여진다. 리소스 그룹을 선택하고 [다음]을 클릭 한다.
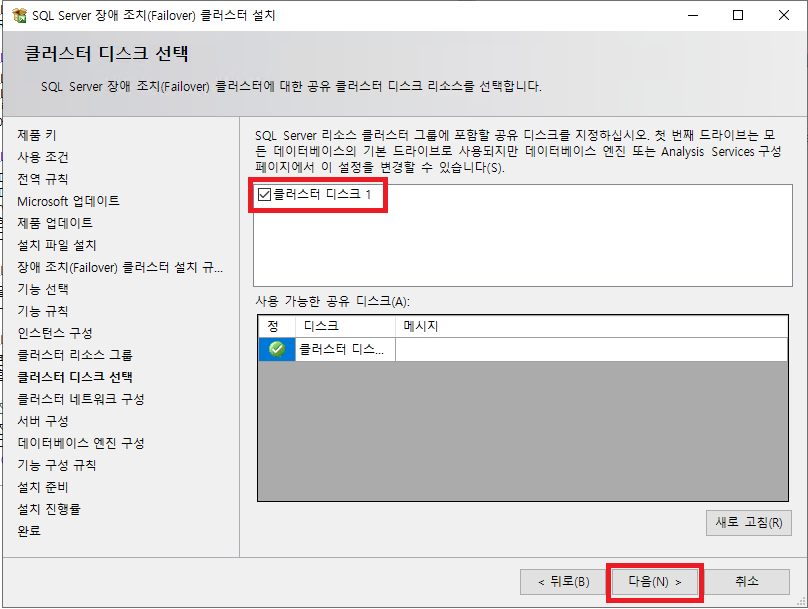
클러스터 디스크 선택 단계에서는 SQL Server에서 사용할 공유 디스크를 선택한다. 이 단계에서 디스크 목록이 나타나지 않는다면 Windows Failover Cluster를 구성할 때 공유 디스크에 대한 설정을 잘못된 것이므로 윈도우 클러스터부터 다시 확인 할 수 있도록 한다. 디스크 선택을 하고 [다음]을 클릭한다.
클러스터 네트워크 구성 단계에서는 SQL Server Cluster에 사용할 IP를 입력한다. 여기에 입력한 IP는 이후 사용자가 접속할 때 사용되는 Cluster IP이다. 클러스터 IP로 접속을 해야 Failover가 발생하였을 때, 활성 된 SQL 서버로 자동으로 연결해 준다. 중복되지 않은 클러스터 IP입력을 하였다면 [다음]을 클릭한다.

서버 구성 단계에서는 SQL Server 서비스에서 사용할 계정과 암호를 입력한다. 이때 도메인 계정을 사용할 수 있도록 한다. 계정과 이름을 입력하였으면 [다음]을 클릭 한다.

데이터베이스 엔진 구성 단계에서는 SQL Server의 접근 방법 및 SQL 관리에 필요한 sa의 비밀번호를 입력한다.

데이터베이스 엔진 구성 단계에서 [데이터 디렉터리] 탭에서는 SQL Server에 필요한 데이터가 위치할 디렉터리를 지정한다. 이 디렉터리 경로는 앞에서 추가한 클러스터 공유 디스크의 위치를 지정한다.

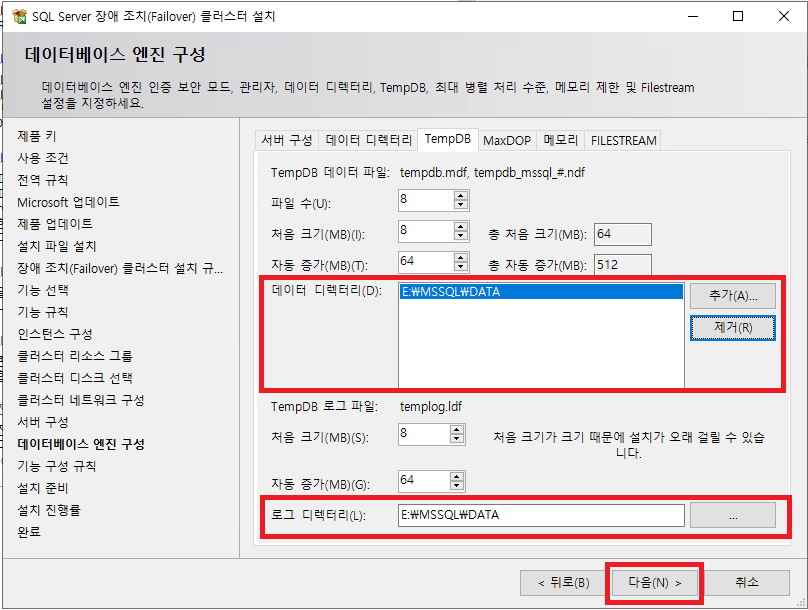
데이터베이스 엔진 구성 단계에서 [TempDB] 탭에서는 SQL Server TempDB가 사용할 디렉터리 경로를 지정한다. 이 디스크는 로컬을 사용해도 되지만, 보통 클러스터 구성시 로컬 디스크는 많은 공간을 할당하지 않기 때문에 용량이 큰 클러스터의 디스크로 지정하였다. 지금까지 구성이 완료되었으면 [다음]을 클릭 한다.
설치 준비 단계에서는 지금까지 설정한 요소들을 정리해서 보여주며 [설치]를 클릭하여 설치를 진행할 수 있도록 한다.

완료 단계에서는 정상적으로 설치가 완료된 것을 보여주며 [닫기]를 클릭 한다.

설치가 완료된 다음, 앞에서 지정한 디렉터리 경로에 SQL Server에 필요한 파일이 생성된 것을 확인할 수 있다.

[Passive서버, 클러스터 노드 추가]
지금까지 Master 서버에서 SQL 클러스터링에 대한 설치를 진행하였고, 이후 단계는 클러스터 노드에 추가할 SQL Server를 설치한다. 이후 과정은 Passive 서버에서 진행하기 때문에 착오가 없도록 한다.
SQL Server 설치 파일을 실행하여 [설치] – [SQL Server 장애 조치(Failover) 클러스터에 노드 추가를 선택 한다.

이후 설치 과정은 이전과 동일한 부분이 있어 그림으로만 대체한다. 필요한 부분에서는 설명을 추가 한다.


앞에서 생성한 인스턴스 클러스터 그룹의 이름을 선택하면 클러스터 노드의 이름을 자동으로 불러와서 보여준다.

클러스터 IP또한 이미 클러스터 구성 시 입력한 정보를 그대로 보여준다.

인스턴스에서 사용할 계정과 암호를 입력한다. 도메인 계정으로 사용할 수 있도록 한다.



클러스터 노드에 추가가 완료된 다음 SQL Server에 접속 테스트를 진행한다. 이때 각 노드의 로컬IP가 아닌 SQL Server Cluster IP를 입력하도록 한다. 로컬IP로 접속할 경우 해당 노드의 인스턴스에 직접 로그인 하기 때문에 Failover가 발생시 활성 서버로 자동으로 연결되지 않는다. 클러스터 IP를 사용할 경우에는 활성 노드로 자동으로 연결해 준다.

서버 이름을 조회해 보면 로컬의 서버 이름이 아닌 클러스터 이름을 보여준다. 그리고 SQL Server 의 클러스터 상태를 조회해 보면 현재 구성되어 있는 모든 노드의 이름을 보여주며 어떤 노드가 활성 상태인지를 보여준다.

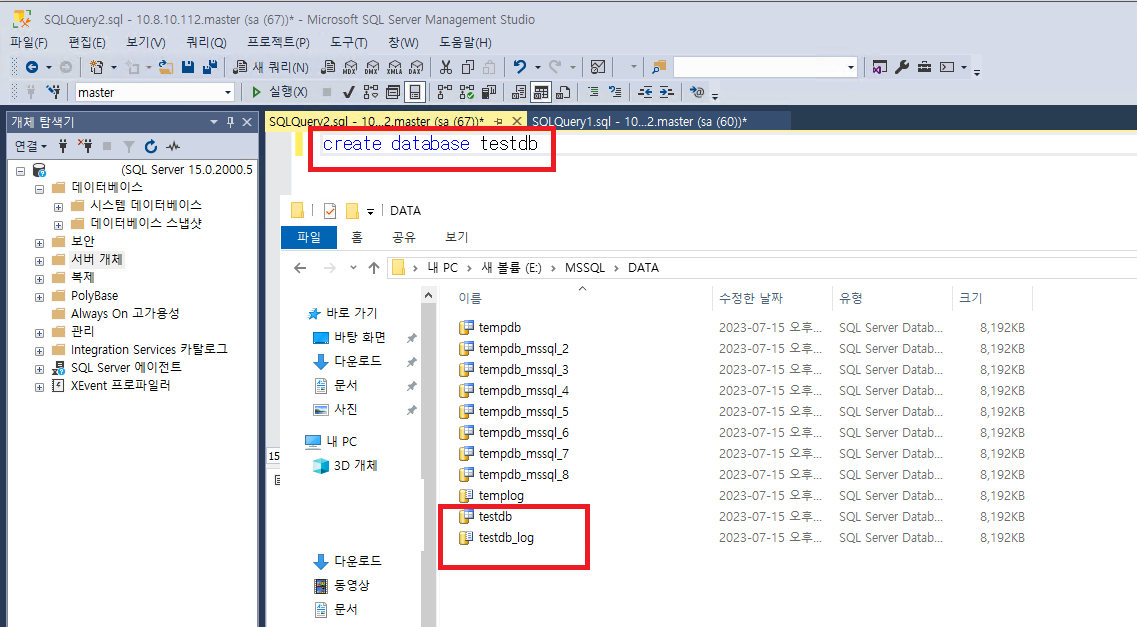
테스트를 위해 TestDB를 생성해 보았는데, 클러스터를 구성할 때 지정했던 디렉터리 경로에 사용자 데이터베이스 파일이 잘 생성되는 것을 확인할 수 있다.
SQL server 장애조치 클러스터를 구성하였을 때, 하나의 서버에 장애가 나도 다른 서버가 그 역할을 대신할 수 있어 가용성을 높일 수 있다. 노드의 개수는 최대 4개 까지 가능하다. 물론 가용성을 높이기 위한 기술로는 클러스터링 외에도 복제, 미러링, AlwaysOn 기술등이 있다. 사용자 환경을 고려하여 최적의 솔루션을 선택하여 가용성을 확보 할 수 있도록 한다.
2023-07-16/ Sungwook Kang / http://sungwookkang.com
SQL Server, MS SQL, SQL Failover Cluster, SQL 장애조치, SQL 클러스터링, 장애조치, SQL 고가용성, 페일오버 클러스터
'SQL Server > SQL Server Tip' 카테고리의 다른 글
| SQL Server Four Part Name 정의 및 PARSERNAME을 활용하여 IP 대역 구하기 (1) | 2025.01.02 |
|---|---|
| SQL Server DELAYED_DURABILITY 옵션으로 트랜잭션 로그 쓰기 성능 개선 하기 (1) | 2022.10.31 |
| SQL Server 에서 AWS S3에 직접 백업하기 (2) | 2022.10.28 |
| VM 환경의 SQL Server에서 할당된 CPU를 모두 사용하지 못하는 현상 (0) | 2020.03.04 |
| SQL Server 복원 성능 최적화 (0) | 2020.02.29 |