과대적합(Over fitting)과 과소적합(Under fitting)
머신러닝에서 학습과정은 패턴을 발견하기 위해 모델링을 만드는 단계라고 할 수 있다. 일반적으로 모델을 만들 때에는 데이터를, 트레이닝 데이터 (training)와 테스트 데이터(test)를 나누어 사용한다. 트레이닝 데이터를 반복적으로 학습함으로써 테스트 데이터 또는 실제 데이터와 가장 유사한 결과를 만들어 내는 것을 목표로 하고 있다.
하지만 트레이닝 데이터와 테스트 데이터가 비슷하다면 모델의 정확도는 매우 높게 나올 것이다. 하지만 모델이 복잡하다면 트레이닝 데이터와 테스트 데이터의 결과는 다르게 나타날 확률이 높다. 일반적으로 트레이닝 데이터는 실제 데이터를 샘플링 하거나 특정 패턴을 인식시키기 위한 데이터로 트레이닝 데이터에 최적화 되어있으면 실제 데이터에서 오차가 발생할 확률이 크다. 그래서 트레이닝 데이터에 대해서는 높은 정확도를 나타내지만 새로운 데이터에 대해서 예측을 잘 하지 못하는 것을 과대적합(Overfitting )이라고 하며, 반대로 트레이닝 데이터 조차도 정확한 결과를 도출하지 못하면 과소적합(Underfitting)이라고 한다. 과대적합과 과소적합 사이에서 최적화된 절충점을 찾아 모델을 만드는 것이 매우 중요하며 트레이닝 데이터에서 생성된 모델이 일반 데이터에 대해 정확하게 예측되는 모델을 “일반화(Generalization) 되었다” 라고 한다.
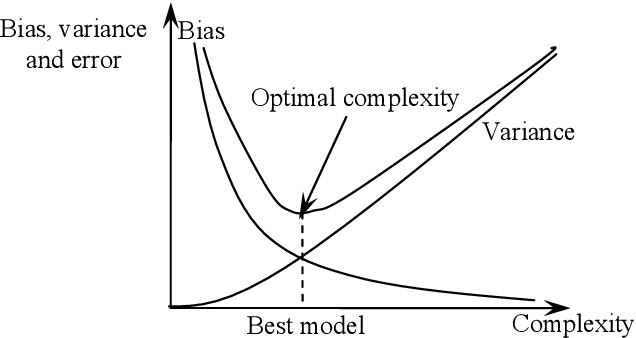
아래 그림은 과소적합(Under fitting)과 과대적합(Over fitting)의 이해를 돕기 위해 그림으로 나타낸 것이다. 과소적합의 경우 데이터를 충분히 반영하지 못해(샘플 개수가 충분하지 않는 경우) 잡음이 많이 섞여 있으며, 과대적합의 경우 불필요한 잡음(noise)를 과도하게 모델링에 반영한 상태이다. 우리는 어느정도 오류(noise)를 허용할지 결정하면서 최적의 모델 값을 도출해야 한다.

과대적합이나 과소적합의 문제를 최소화하고 정확도를 높이는 가장 좋은 방법은 더 많고 다양한 데이터를 확보하고, 그 데이터에서 다양한 특징(feature)들을 찾아서 학습에 사용하는 것이다. 즉, 트레이닝 데이터에 따라, 생성된 모델의 정확도가 결정되므로 트레이닝 데이터 세트를 잘 만드는 것이 중요하다.
[참고자료]
https://brunch.co.kr/@gimmesilver/44
https://ko.d2l.ai/chapter_deep-learning-basics/underfit-overfit.html
2020-03-18/ Sungwook Kang / http://sungwookkang.com
인공지능, Artificial Intelligence, 머신러닝, Machine Learning, 딥러닝, Deep Learning, 과대적합, 과소적합, Over fitting, Under fitting
'SW Engineering > 머신러닝 딥러닝' 카테고리의 다른 글
| Python에서 Tesseract 사용하기 (0) | 2020.12.19 |
|---|---|
| Tesseract를 활용한 이미지 속 문자인식 (0) | 2020.12.18 |
| 경사 하강법(Gradient Descent) (0) | 2020.03.16 |
| 순전파(Feedforward)와 역전파(Backpropagation) 개념 (1) | 2020.03.15 |
| 다층 퍼셉트론 (Multi-layer Perceptron) (0) | 2020.03.12 |